Ophthalmology and Vision Care
OPEN ACCESS | Volume 6 - Issue 1 - 2026
ISSN No: 2836-2853 | Journal DOI: 10.61148/2836-2853/OVC


Gabriella Bulloch1,2, Ishith Seth2*, Zhuoting Zhu2, Fiona Jane Stapleton3, Adrian Fung4, Zachary Tan2, Hugh R. Taylor1,2
1 Faculty of Science, Medicine and Health, University of Melbourne, Victoria, 3051, Australia
2 Department of Ophthalmology, Centre of Eye Research Australia, Victoria, 3004, Australia
3 School of Optometry and Vision Science, University of New South Wales, New South Wales, 2052, Australia
4 Faculty of Medicine and Health, University of Sydney, New South Wales, 2006, Australia
*Corresponding Author: Ishith Seth, Department of Ophthalmology, Centre of Eye Research Australia.
Received Date: February 23, 2023
Accepted Date: February 28, 2023
Published Date: March 03, 2023
Citation: Bulloch G, Seth I, Zhu Z, Fiona J Stapleton, Fung A. (2023) “Artificial Intelligence Applications, and Performance Metrics in Ophthalmology: A Systematic Review and Meta-Analysis”, Ophthalmology and Vision Care, 3(1); DOI: http;//doi.org/03.2023/1.10238
Copyright: © 2023 Ishith Seth. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Purpose: To evaluate the overall performance of various Artificial intelligence (AI) models in ophthalmology for the diagnosis of various ophthalmic diseases despite of variations in methodology, platforms built, and workflows. AI technologies can revolutionize ophthalmology and vision sciences through automating image analysis.
Methods: A systematic search on EMBASE, Medline (via PubMed), CINHAL, Cochrane Library, Clinicaltrial.gov, Google Scholar, Scopus, and Web of Science was conducted for studies published up to March 2022. Two authors independently screened all titles and abstracts against predefined inclusion and exclusion criteria and extracted data. The Quality Assessment of Diagnostic Accuracy Studies (QUADAS) tool was used to assess for risk of bias and applicability. The pooled sensitivity (SE), specificity (SP), accuracy, and area under the curve (AUC) were estimated using a random-effects model with a 95% Confidence Interval (CI). An assessment of publication bias was performed. The protocol of this meta-analysis was published online PROSPERO under registration number CRD42021242593.
Results
Our meta-analysis included a total of 42 studies that met the inclusion criteria. The MESSIDOR database was most frequently used for training and testing among selected studies. Pooled performance of AI algorithms for included ophthalmic disorders were SE=92.93% (95% CI 91.01, 94.86), SP=88.73% (95% CI 83.55, 93.91), accuracy =94.62% (95% CI 91.98, 97.27), and AUC=0.96 (95% CI 0.94, 0.98).
Conclusion
Currently published AI algorithms are highly accurate for diagnosing ophthalmic diseases and have the potential to unlock population-based screening for common eye conditions. The adoption of standardized reporting frameworks and more prospective/randomized control trials are currently required to improve generalizability of AI for clinical practice.
Introduction
There are 2.2 billion people with visual impairment globally, with almost half of these being preventable or yet to be addressed.1, 2 Vision impairment without intervention leads to significant morbidity, increases health services demand, and carries a global financial burden of an estimated $244 billion annually.3 With non-communicable diseases like diabetes and heart disease becoming increasingly common in young populations, retinal pathologies resulting from comorbidities have become more frequent.4 Similarly, retinopathy of prematurity (ROP), the most common cause of blindness in children worldwide, carries an enormous healthcare burden subserved by limited neonatal intensive care services and late diagnosis.5 Improving access to eye disease screening is a sensible solution, although as the global population rises, demographics shift towards ageing populations, and clinician availability remains insufficient, these challenges bottleneck eye care services.6
Many believe artificial intelligence (AI) is a solution for the practical and financial challenges that inhibit population-based screening and diagnosis of eye diseases.7 AI utilizes computer-based algorithms and novel software to replicate human intelligence. Its application effectively replaces problem-solving and practical tasks that are otherwise laborious and time-inefficient in domains of society which are bottlenecked by imbalanced service-to-demand ratios.8 AI technologies have established high efficiency, accuracy, and precision within medicine, and has already demonstrated applications to ophthalmology through data evaluation, segregation, electronic diagnosis, and potential outcome prognosis.9,10 Machine learning (ML) is a subset of AI that learns automatically from data sets in the absence of explicitly programmed rules.11 Deep learning (DL) is a subclass of ML and trains itself using multiple layers of neural networks which are adaptable programming units inspired by the structure of human neurons. DL has demonstrated significant potential in classification and feature extraction and has the ability to learn complex representations from raw data to improve pattern recognition.12, 13 Its image recognition and computer vision have made it a favorable tool for the grading of images, and individual studies show it has improved image analysis for diagnosis and preditction.13, 14
AI’s accuracy in automated diagnosis, time efficiency, and outcome prediction has enabled desirable applications within healthcare, but for its successful implementation within clinical practice AI needs to ensure its accuracy is not inferior to clinicians.15 Variations in methodology and platforms built for DL give an overall illusion its clinical validity is not yet warranted. Indeed, various workflows for DL, variations in testing and validation set sizes, fluctuating disease definitions, and the absence of external validation by clinical experts may cloud the establishment of ground truth and diminish its trustworthiness.14,15 This heterogeneity also complicates a formal evaluation of AI studies and is yet to be accounted for by the integration of specific AI/ML reporting frameworks.16 Ethical legislation surrounding the use and scrutiny of AI continues to be of concern to healthcare providers, and bench to bedside challenge can only be overcome by conducting studies that assess AI to a high degree of scrutiny not just in performance, but equally in ethics, effectiveness, replicability, and transparency.17, 18
Considering the timeliness of AI, this systemic review and meta-analysis investigated and scrutinized the ability of AI to diagnose all ocular disorders that satisfied our search criterion. The advantages and limitations of AI in the management of retinal disorders were also explored.
Methods
This study was performed according to the Preferred Reporting Items for Systematic Reviews and Metanalyses (PRISMA) statement.19 The protocol of this meta-analysis was published online at the International Prospective Register of Systematic Reviews (PROSPERO) under registration number (CRD42021242593). There were no study restrictions imposed on different populations, races, ethnicity, and origin.
Literature Search
A comprehensive systematic search on EMBASE, Medline (via PubMed), CINHAL, Cochrane Library, Clinicaltrial.gov, Google Scholar, Scopus, and Web of Science was conducted for studies published from January 2009 to March 2022. A variety of all possible keywords like ‘artificial intelligence and ophthalmology’, ‘deep learning and ophthalmology’, ‘machine learning and ophthalmology’, ‘convolutional neural network and ophthalmology’, ‘deep neural network and ophthalmology’, ‘automated technique and ophthalmology’ were listed to avoid any data loss. No age, gender, and population filters were imposed. Two authors independently screened all titles and abstracts against predefined inclusion and exclusion criteria. Any differences in articles selected by the two were discussed with third author to reach a decision regarding inclusion. The reference lists of screened articles were also reviewed for any missed literature.
Inclusion and Exclusion Criteria
The established inclusion criteria were as follows: (1) all published data reporting the use of AI, DL, or ML in ophthalmology, (2) studies that evaluated the sensitivity (SE), specificity (SP), accuracy, and area under ROC curve (AUC) in their study OR any one of the mentioned parameters, (3) studies provided an outcome of AI in ophthalmology for a pathological condition against healthy population sample sets of normal eyes, retinal images, and photographs, (4) studies provided information about databases/methodology used, (5) studies clearly described the type of AI used and detected eye disease, (5) studies published in English. All full-text studies including randomized control trials, original research articles, descriptive and analytic studies (cohort or case-control) were included.
The exclusion criteria were as follows: (1) studies that did not measure conclusive performance outcomes, (2) parameters used to analyze data were different from defined ones, (3) incomplete studies, (4) poster or scientific presentations, (5) reviews, meta-analysis, opinion articles, letter to editor, short communications, and case reports.
Outcome Measures
The primary outcome measures assessed the performance of AI in ophthalmology including SE, SP, accuracy, and AUC. Secondary outcomes were not defined in advance.
Data extraction and quality assessment
Data extraction was done twice as per defined inclusion criteria and keywords, to avoid any risk of bias and possibility of missing data.20 Data extracted include first author's name, publication year, used dataset or methodology information, measured parameters in terms of SE, SP, accuracy, and AUC. We used the Quality Assessment of Diagnostic Accuracy Studies-2 (QUADAS-2) tool for assessing the quality of included diagnostic studies. The QUADAS-2 scale comprises four domains: patient selection, index test, reference standard, and flow and timing. The first three domains are used for evaluating the risk of bias in applicability. The overall risk of bias was categorized into three groups (low, high, and unclear risk bias).
Data Synthesis
Statistical analyses were conducted using review manager (RevMan version 5.4, Cochrane collaboration, Oxford, UK). Overall performance measures along with 95% confidence intervals (CIs) range were calculated for all defined primary indicators i.e., sensitivity, specificity, accuracy, and AUC, and were represented by forest plot. A standard error of 0.05 was observed in all tests. Data heterogeneity was checked, and publication bias was assessed using Egger's test. Further, a Youden plot was generated against sensitivity and specificity measures to detect the test accuracy, and Youden’s index was calculated.
Results
Study Selection
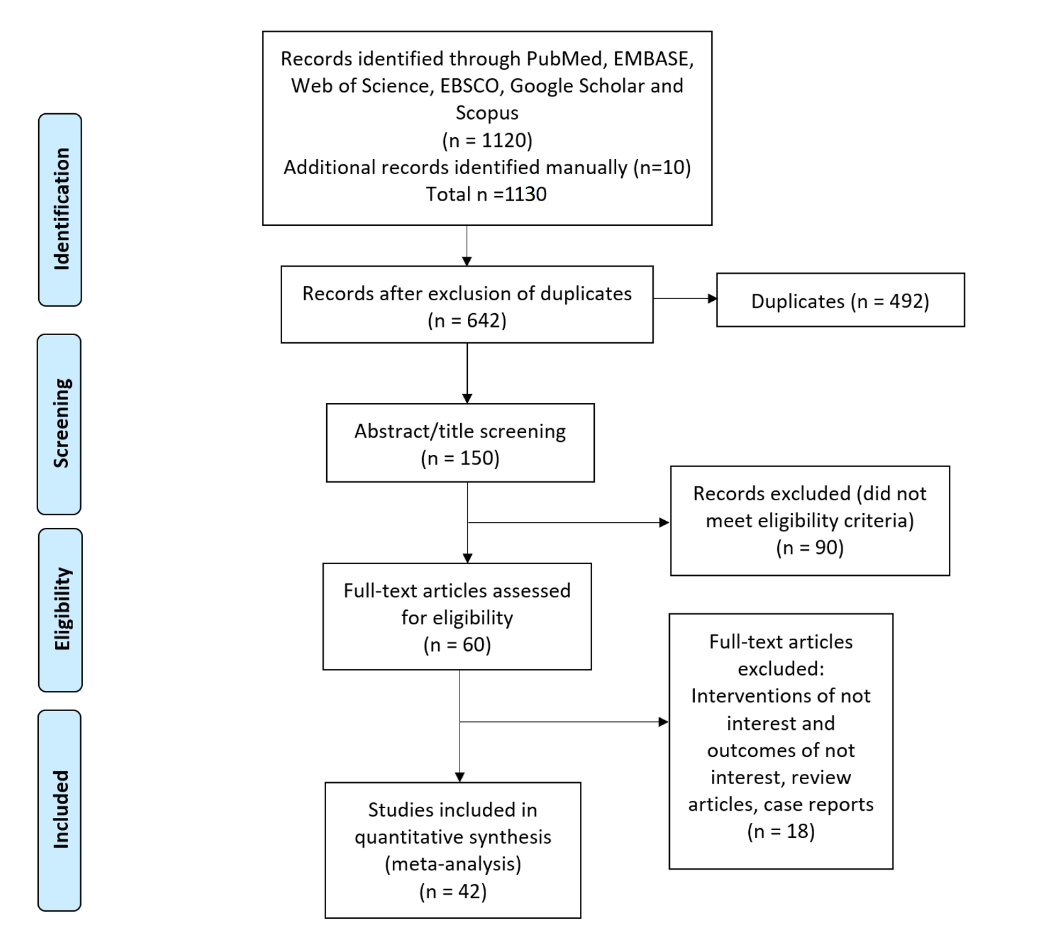
A total of 1130 potentially eligible records were extracted in the initial data retrieval process. During the screening, 488 records were eliminated due to duplication, and 492 were eliminated based on the study title and abstract. Of the 150 remaining studies reviewed, 90 were excluded for not meeting inclusion criteria, and 18 were conference abstracts or poster presentations. Finally, 42 studies were included in the final meta-analysis.12,21-62 The process used to search and identify studies is illustrated in Figure 1.
Figure 1: Summary of study selection process Preferred Reporting Items for Systematic Review and Meta-Analyses flow diagram
Study Characteristics
Selected studies were analyzed for the performance of AI in the diagnosis of common eye diseases, dataset/methodology used, AI model tested, validation performed, and reference standards used to assess performance. These findings are described in Supplementary Table 1. Indicators of performance including specificity, sensitivity, accuracy, and AUC are summarized in Table 1.
Table 1: Performance indicators in selected studies
|
Sl No |
Author's Name, year and Reference number |
Dataset |
Sensitivity (%) |
Specificity (%) |
Accuracy (%) |
Area under ROC Curve |
|
1 |
Aquino et al., 2009 |
MESSIDOR |
- |
- |
98.83 |
- |
|
2 |
Haloi et al., 2015 |
MESSIDOR, ROC |
97 |
96 |
96 |
0.982 |
|
3 |
Ahmed et al., 2015 |
MESSIDOR |
- |
- |
97.8 |
- |
|
4 |
Liskowski et al., 2016 |
DRIVE, STARE, CHASE DB |
- |
- |
97 |
0.99 |
|
5 |
Asoaka et al., 2016 |
Private: 171 |
- |
- |
- |
0.926 |
|
6
|
Grinven et al., 2016 |
MESSIDOR |
91.9 |
91.8 |
- |
0.972 |
|
EyePACS |
83.7 |
85.1 |
- |
0.895 |
||
|
7 |
Abràmoff M et al., 2016 |
MESSIDOR -2 |
96.8 |
87 |
- |
_ |
|
8 |
Colas E et al., 2016 |
EyePACS |
96.2 |
66.6 |
- |
0.946 |
|
9
|
Gulshan et al., 2016 |
EyePACS-1, |
90.3 |
98.1 |
- |
0.991 |
|
MESSIDOR -2 |
87 |
98.5 |
- |
0.99 |
||
|
10 |
Gargeya et al., 2017 |
EyePACS, MESSIDOR e-Optha2 |
94 |
98 |
- |
0.97 |
|
11
|
Quellec et al., 2017
|
Kaggle, |
- |
- |
- |
0.954 |
|
E-Ophtha |
- |
- |
- |
0.949 |
||
|
DIARETDB |
- |
- |
- |
0.955 |
||
|
12 |
Ambrósio R Jr et al., 2017 |
(RF/LOOCV) |
100 |
100 |
- |
0.996 |
|
13 |
Takahashi et al., 2017 |
9939 images (Posterior Pole Photographs) |
- |
- |
80 |
- |
|
14
|
Tan et al., 2017 |
CLEOPATRA |
- |
- |
87.58 |
- |
|
|
- |
- |
71.58 |
- |
||
|
15
|
Oliveira et al., 2018
|
DRIVE |
80.39 |
98.04 |
95.76 |
0.9821 |
|
STARE |
83.15 |
98.58 |
96.94 |
0.9905 |
||
|
CHASE DB1 |
77.79 |
98.64 |
96.53 |
0.9855 |
||
|
16
|
Schmidt-Erfurth U et al., 2018
|
Coherence Tomography (OCT) |
- |
- |
- |
0.68 |
|
- |
- |
- |
0.8 |
|||
|
17 |
Lin et al., 2018 |
Kaggle |
73.24 |
93.81 |
86.1 |
0.92 |
|
18 |
Chakravarty et al., 2018 |
REFUGE |
- |
- |
- |
0.9456 |
|
19 |
Li Z et al., 2018 |
Private:48000+ |
95.6 |
92 |
|
0.986 |
|
20 |
Chai Y et al., 2018 |
Private: 2554 |
- |
- |
91.51 |
- |
|
21
|
Mitra et al., 2018
|
MESSIDOR |
- |
99.14 |
99.05 |
- |
|
EyePACS |
- |
98.17 |
98.78 |
- |
||
|
22 |
Liu et al., 2018 |
HRF, RIM-ONE |
86.7 |
96.5 |
91.6 |
0.97 |
|
23
|
Orlando et al., 2018 |
e-optha |
- |
- |
- |
0.8812 |
|
MESSIDOR |
- |
- |
- |
0.8932 |
||
|
24 |
Lam et al., 2018 |
EyePACS, e-optha |
- |
- |
98 |
0.95 |
|
25 |
Grassmann et al., 2018 |
AREDS and KORA |
94.3 |
84.2 |
- |
- |
|
26
|
Zhang et al., 2018
|
DRIVE |
87.23 |
96.18 |
95.04 |
0.9799 |
|
STARE |
76.73 |
99.01 |
97.12 |
0.9882 |
||
|
CHASE DB1 |
76.7 |
99.09 |
97.7 |
0.99 |
||
|
27 |
Zhou W et al., 2018 |
MESSIDOR |
- |
- |
99.83 |
- |
|
28 |
Al-Bander et al., 2018 |
MESSIDOR and Kaggle |
- |
- |
97 |
- |
|
29 |
An G et al., 2019 |
Machine Learning |
- |
- |
- |
0.963 |
|
30 |
Medeiros et al., 2019 |
Deep-Learning (DL) |
- |
- |
83.7 |
- |
|
31
|
Lin, H. et al., 2019 |
CC Cruiser |
- |
- |
87.4 |
- |
|
Kaggle |
- |
- |
70.8 |
- |
||
|
32 |
Zéboulon P et al., 2020 |
Machine learning algorithm |
100 |
100 |
99.3 |
- |
|
33 |
Varadarajan AV et al., 2020 |
EyePACS |
85 |
80 |
- |
0.89 |
|
34 |
Ahn H et al., 2020 |
Artificial intelligence ECcSMOTE II |
- |
- |
99.05 |
- |
|
35 |
Rim TH et al., 2020 |
Deep-Learning (DL) Algorithms RetiSort |
- |
- |
99 |
- |
|
36 |
Lee J et al., 2020 |
Machine learning classifiers |
- |
- |
- |
0.881 |
|
37 |
Huang Y-P et al., 2020 |
VGG19 model |
96.6 |
95.2 |
96 |
- |
|
38 |
Tham YC et al., 2020 |
ResNet-50 |
90.7 |
86.8 |
- |
0.94 |
|
39 |
Son J et al., 2020 |
IDRiD, e-Ophtha, MESSIDOR |
97.2 |
96.8 |
- |
0.99 |
|
40 |
Li Z et al., 2020 |
Deep Learning |
99.5 |
99.5 |
99.5 |
1.00 |
|
41 |
Dai L et al., 2021 |
DeepDR |
92.8 |
81.3 |
- |
0.95 |
|
42 |
Luo X et al., 2021 |
EfficientNet-B3 |
99.49 |
97.86 |
99.02 |
0.99 |
Quality assessment and publication bias
The quality of included studies was assessed using the QUADAS-2 tool and was presented in Supplementary Table 2. For patient selection and index tests, all studies were identified to exhibit a low risk of bias. An unclear risk of bias was found in flow and timing as well as reference standard domains for all included studies. Egger's test for a regression intercept gave a P-value of 1.000, indicating no evidence of publication bias.
Outcome measures
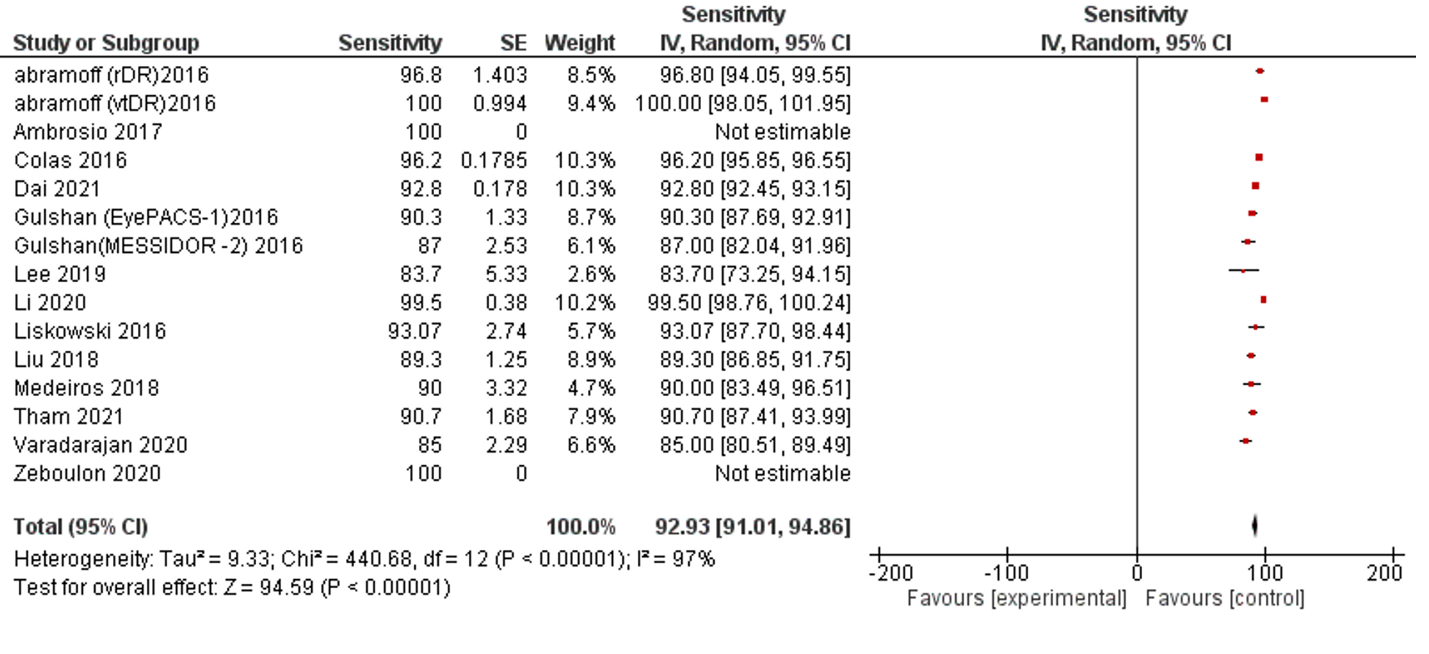
Of the 42 selected studies, 13 studies, and 15 datasets reported SE performance. The data indicators represent the data as valid with low error and no publication bias. The pooled SE of reviewed publications was 92.93% (95% CI 91.01, 94.86). No studies reported lower than 80% of SE, while Five studies reported 80-90%, Seven studies with >90%, and Three studies with 100 % SE. The I2 was 97%. (Table 1, Figure 2).
Figure 2: Forest plot of sensitivity analysis of selected studies
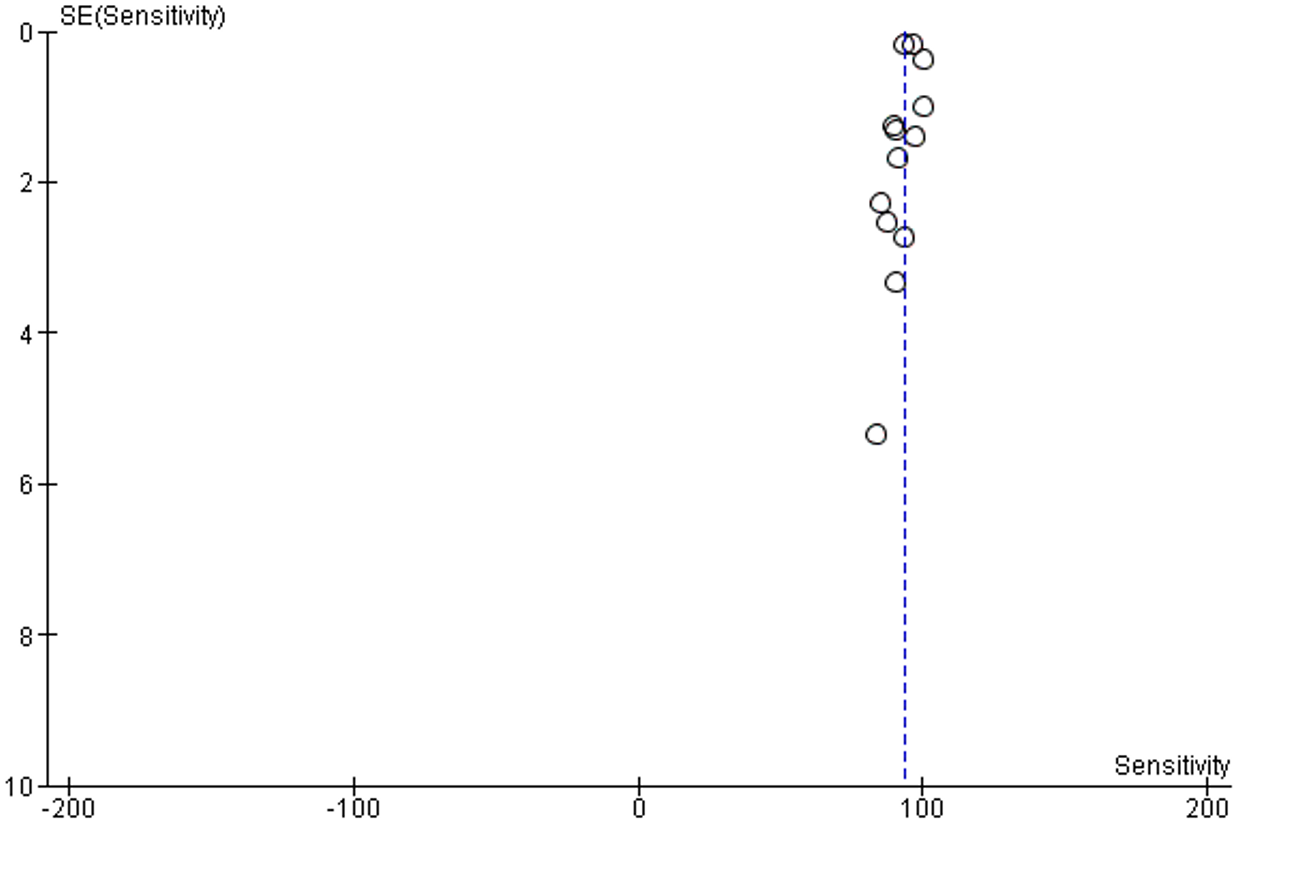
Supplementary Figure 1: Funnel plot of publication bias of sensitivity analysis
No publication bias was detected, Supplementary figure 1.
Twelve studies and 14 datasets reported SP performance. Only one study reported less than 70% SP (66.6%). All remaining studies reported more than 80% SP of AI and 2 studies reported 100% SP (Table 1, Figure 3).
Figure 3: Forest plot of specificity analysis of selected studies
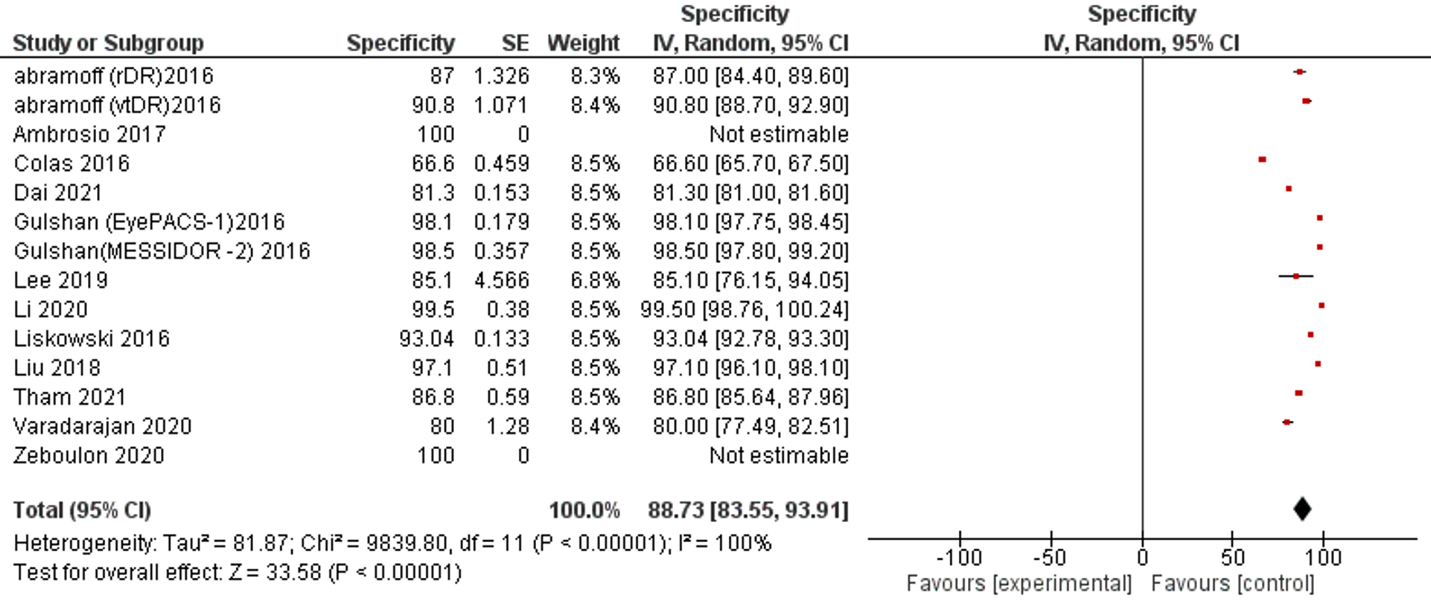
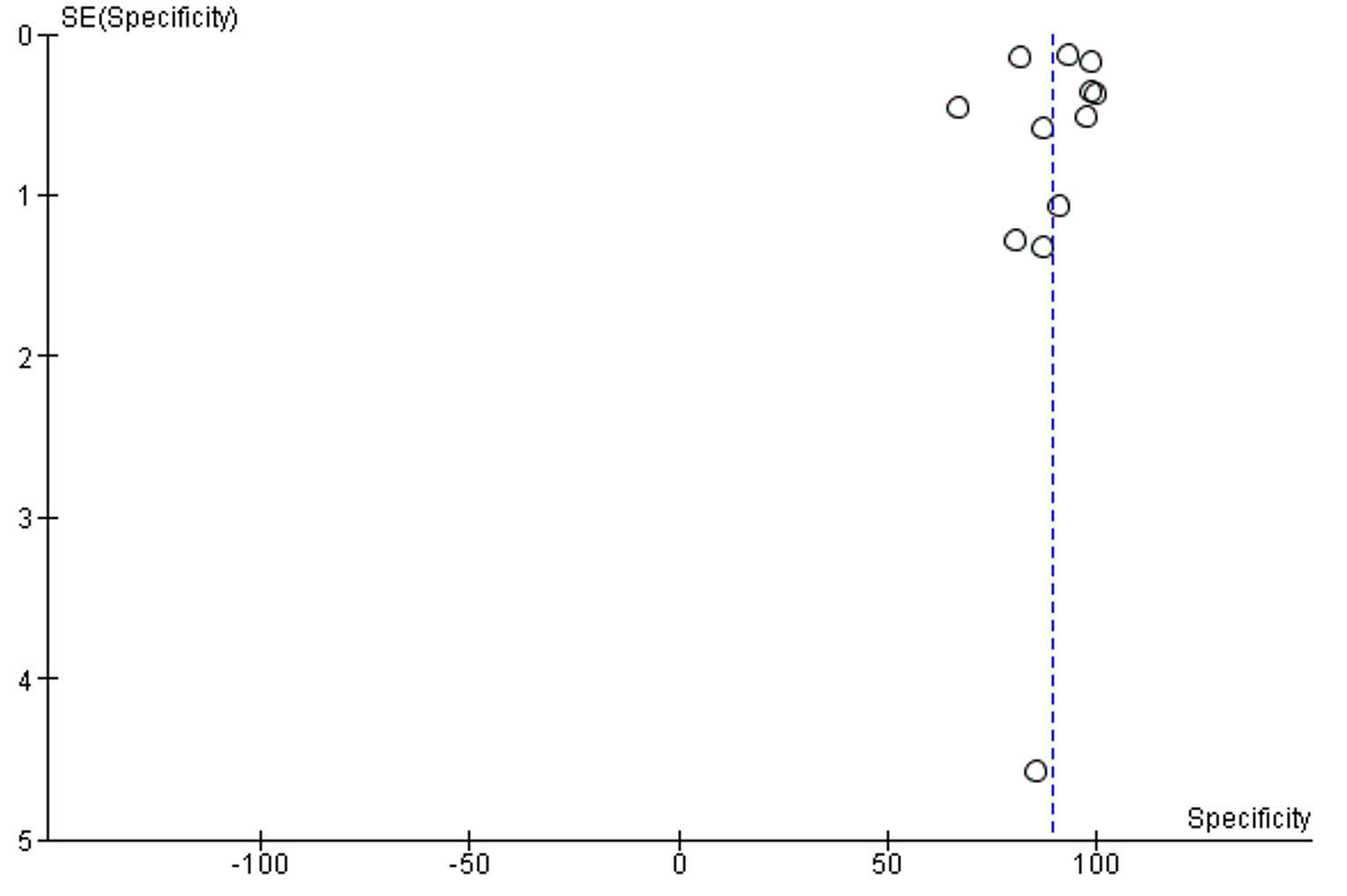
The overall SP of reviewed publications was 88.73% (95% CI 83.55, 93.91). The I2 of included studies was 100% . No publication bias was detected, Supplementary figure 2.
Supplementary Figure 2: Funnel plot of publication bias of specificity analysis
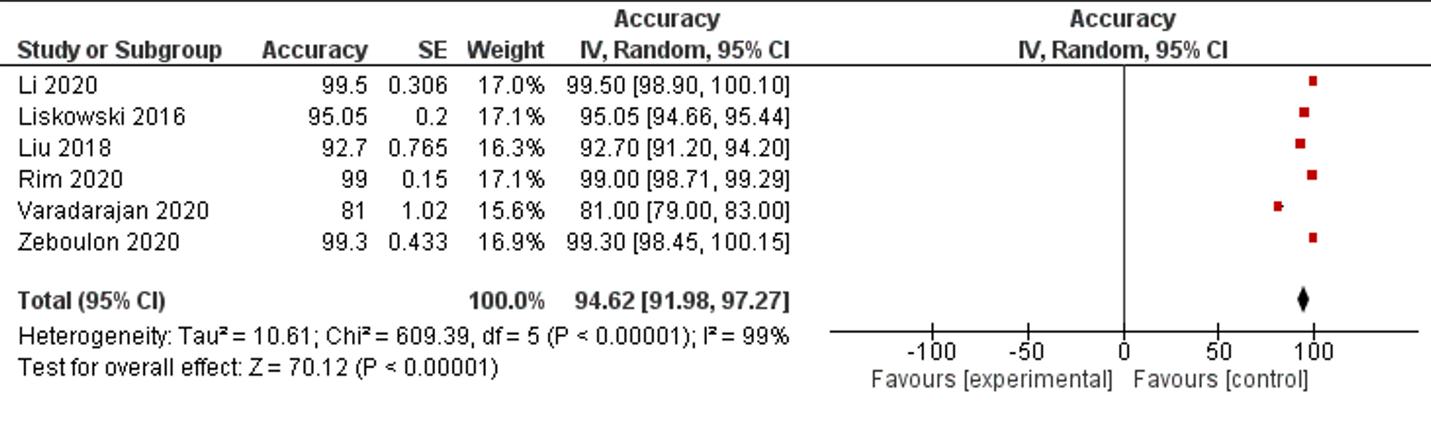
Accuracy is the second most reported performance indicator, which was reported in Six studies among 42 selected studies. Only one study reported less than 85% accuracy, five studies reported less than 90% accuracy. The overall accuracy of AI among selected studies was 94.62% (95% CI 91.98, 97.27), (Table 1, Figure 4).
Figure 4: Forest plot of accuracy measurement of selected studies
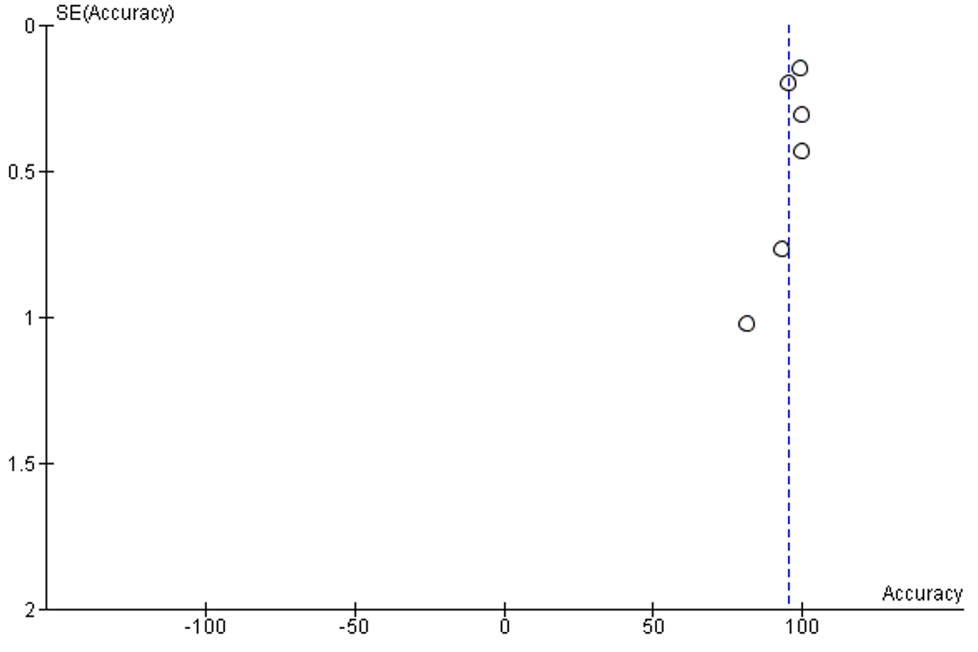
The I2 of included studies was 100%. No publication bias was detected, Supplementary figure 3.
Supplementary Figure 3: Funnel plot of publication bias of accuracy analysis
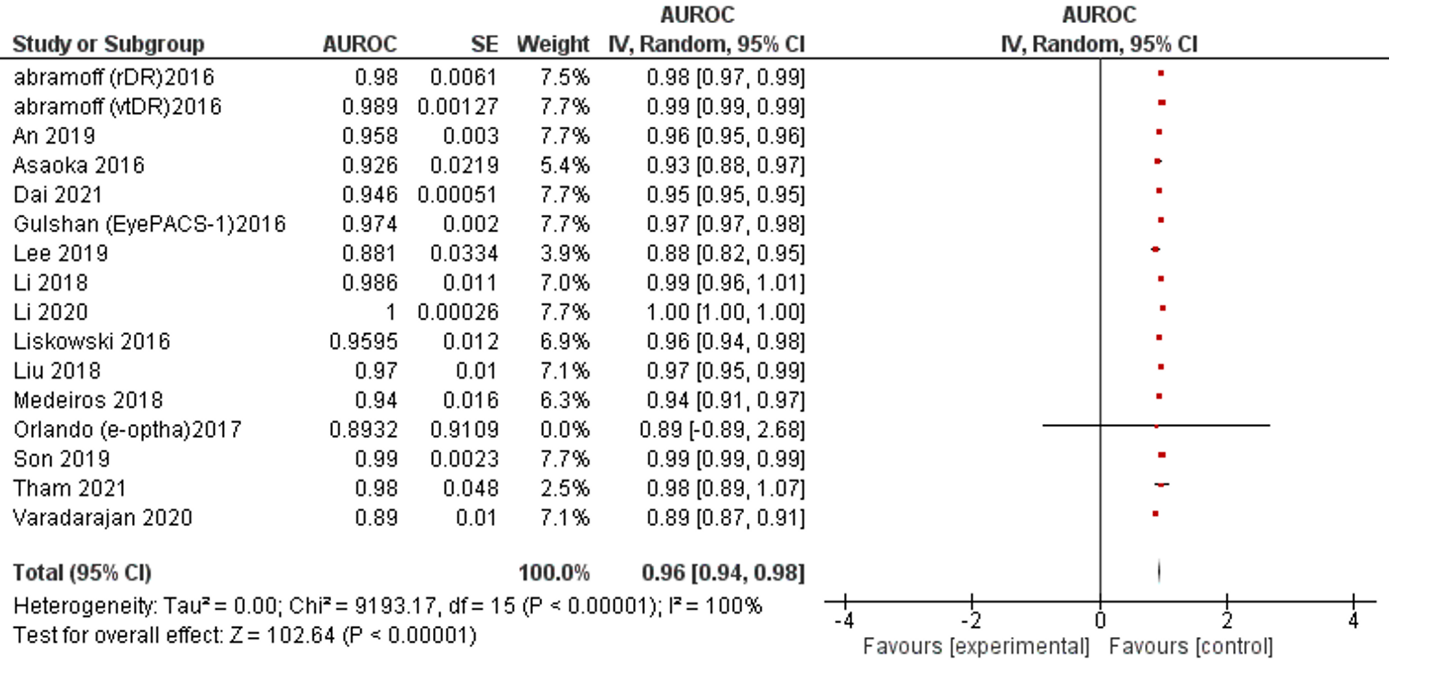
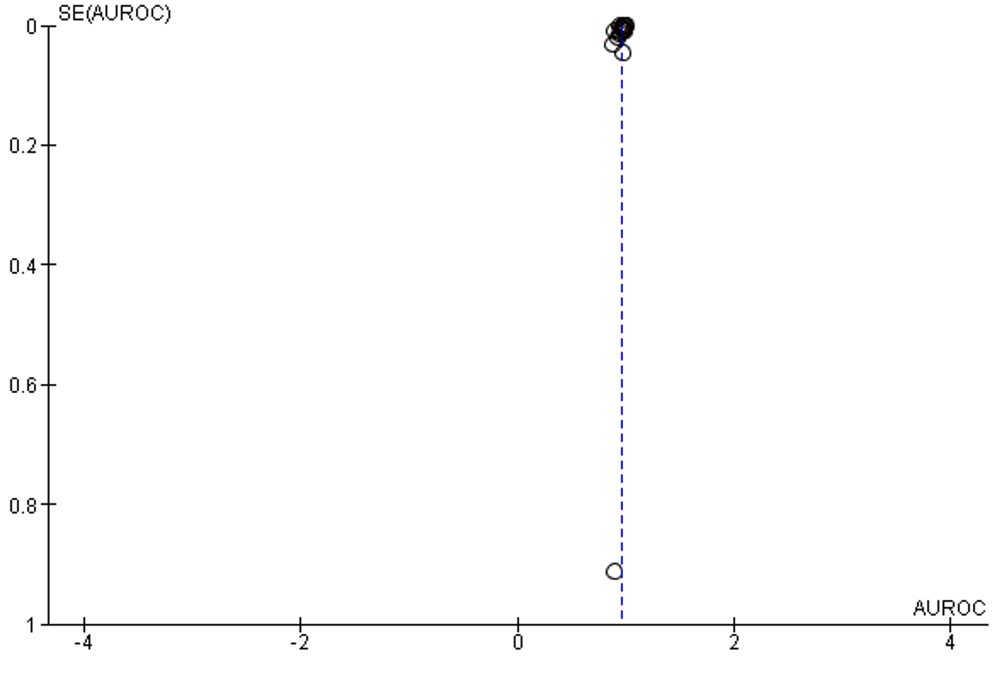
AUC is the most reported indicator of AI performance, which represents a combined performance measure across all viable classification thresholds. AUC values between 0.8 to 0.9 are considered excellent, and more than 0.9 considered to be outstanding.63 The overall AUC of studies was 0.96 (95% CI 0.94 – 0.98). All reported results fall in the excellent and outstanding categories. The I2 of included studies was 100% (Table 1, Figure 5).
Figure 5: Forest plot of area under receiver operating characteristics curve of selected studies
No publication bias was detected, Supplementary figure 4.
Supplementary Figure 4: Funnel plot of publication bias of calculation of area under the ROC curve
Test of Accuracy
Youden’s Index is a combined measure of SE and SP for indexing test accuracy (Supplementary Figure 5).
Supplementary Figure 5: Youden’s plot of sensitivity and specificity of selected studies
The maximum value of Youden’s index is 1 indicating a perfect test, while the minimum value possible is 0 when the test has no diagnostic value. This study recorded a Youden’s index of 0.85, indicating a high accuracy across studies.
Discussion
This systematic review and meta-analysis included studies up to March 2022 and demonstrated AI achieved a high performance for the recognition of eye diseases. Performance in sensitivity was 93%, specificity 88.73%, accuracy 94.62%, and AUC 0.96. Of the various AI platforms used, MESSIDOR database was most frequently utilized for training and testing amongst our selected studies. A Youden’s index of 0.85 indicated that pooled estimates were of high accuracy. These results suggest AI technologies may assist in the diagnosis of eye diseases and improve access to screening and management of these conditions.64
AI in ophthalmology has gained popularity over the last decade, evidenced by the plethora of publications accrued and innovations since acquired.65 Our study set ranged from 2009-2022 and despite the impressive performance, significant methodological deficits were noted amongst the 42 included studies. After QUADAS assessment it was clear most retrospective studies included data labels and quality reference standards which were not primarily intended for the purpose of measuring AI’s utility and performance. As a result, the translation of these results to real-world outcomes may be limited. Furthermore, smaller training sets in the learning phase of some DL models may lead to poor prediction accuracy due to overfitting, or rather them being insufficient representatives of disease.66 If this occurs, accuracy suffers in the long term and the model may miss important features of a disease or illness. External validation is therefore critical to the evaluation of a model’s accuracy and ensuring a ground truth is addressed. Unfortunately, many studies did not perform an external validation of the model in a separate test dataset which is crucial to ensuring real-world clinical performance of DL, eliminating bias, and ensuring diagnosis/prediction accuracy of the model.13 Low evaluative measures limit the validity of performance parameters particularly AUC, and hints to the presence of unpublished publication bias. Robustly reported evaluative measures would have provided an objective standard and needs to be confronted in future publications to ensure reliability of AI and enable comparison between DL models.29, 42, 43, 49, 51
In the past, AI has lacked directives that would remove heterogeneity between studies and allow its transition from bench to bedside. To improve its integrity, guidelines including the SPIRIT-AI67, CONSORT-AI68, STARD-AI15, and TRIPOD-AI69 statements are currently being developed and phased into studies under published guidance from the EQUATOR network. SPIRIT-AI67 and CONSORT-AI68 statements are the first international standards for clinical trials of AI systems and aim to improve the standard of design and delivery by providing completeness of intention and transparency of reporting. In contrast, STARD-AI15 and TRIPOD-AI69 are specific to studies investigating diagnostic accuracy and prognostic modelling, and aim to improve methodology reporting and outcome measures, and to standardise nomenclature. This is a significant step for AI because reporting of clinical prediction models is currently poor and a threat to its clinical integrity. The implementation of these protocols will be a welcomed improvement to the field of AI to ensure its performance and safety in clinical practice.
In addition, few studies were randomized control trials (RCT) or prospective studies, while a large proportion were retrospective cohort studies. Using retrospective data is certainly a convenient and less costly way of testing AI’s accuracy which, by design, inherently demands large quantities of data to optimize its neural networks. An unfortunate side effect is the current literature does not compare AI’s performance against experts in a clinical, real time setting. Hence there exists a large potential for the development of prospective studies and RCTs which may compare the applicability of these algorithms in clinical practice. If undertaken, it cannot be underestimated how important these applications can be for rural and developing areas particularly. AI techniques can smoothen the multistage process of screening, staging and treatment decision for a condition, thereby sharing the burden of clinical experts and providing a greater population outreach.70 In Australia, remote and regional communities are associated with less frequent eye checkups and are even lower in First Nations people.71 Indigenous Australians also present later to eye health professionals for a presenting problem relative to Non-Indigenous Australians, predisposing them to preventative ocular diseases.71 As a result, there have historically been higher instances of pterygium, cataract, ocular trauma, and glaucoma in rural populations.72 Here, AI has the potential utility of providing basic eye health reports and information to remote regions that lack access to consistent eye health-care services. Moreover, AI systems will be invaluable to Indigenous communities particularly by negating many current concerns pertaining to Non-Indigenous clinicians, interpreters, cultural and language barriers which currently contribute to health gaps between Indigenous and Non-Indigenous Australians.73, 74 To date, only few AI studies have been the subject of prospective cohort studies but the preliminary results have so far been positive.73-77
Prediction tools are another innovative and potentially positive application for AI, especially in comorbid populations where retinopathies and retinal structure abnormalities are associated with comorbidities. In contrast to classical prediction models that rely on cross-sectional data and are prone to overfitting, AI techniques can incorporate longitudinal data which optimizes prediction over time without human intervention.78-81 Despite these unique characteristics, prediction models are not yet optimized and are subject to the same scrutiny as other AI technologies within medicine. Arcadu et al predicted DR worsening in 529 patients at 6, 12, and 24 months with an overall AUC of 0.68 using deep CNN (DCNN) and random forest aggregation.82 Schmidt-Erfurth et al successfully predicted a 2-year progression of intermediate AMD to choroidal neovascularization or geographic atrophy in 495 eyes with AUC= 0.68 & 0.80, respectively.36 Lastly, a recent systematic review summarized the ability of various DL models to isolate and predict geographic atrophy progression, an end-stage feature of chronic AMD, reported a low R2value of 0.32 in the studies that predicted progression.83 An online survey of clinicians on the use of AI in ophthalmology, dermatology, radiology and radiation oncology revealed improved access to disease screening as the greatest perceived advantage to the use of AI.84 Whilst AI shows potential utility in ophthalmology for disease prediction and progression, its reliability remains to be optimized and is an ongoing area of emerging research.
Currently, regulatory agencies such as the United States Food and Drug Administration (USFDA) and Therapeutic Goods Australia (TGA) loop AI/ML under the umbrella of software as a medical device (SaMD)85, 86 when they are being approved for therapeutic use. In 2018 the first DL system in ophthalmology to be cleared by USFDA was IDx-DR for automated diagnosis of more-than-referable DR.87 IDx-DR utilizes AI as a fundus image analyzer and provides diagnosis and referral to a specialist if a pathology is detected. In 2020 EyeArt also achieved USFDA clearance for detecting clinical DR and vision-threatening DR retinopathy in adults with diabetes.88 Both technologies received 510(k) clearance by the U.S. Food & Drug Administration for DR meaning the technologies demonstrate themselves as safe and effective compared to a similar, legally marketed algorithm. These clearances are landmark occurrences for AI/ML in Ophthalmology because pathways by governing regulatory bodies are evolving entities with stringent criteria needed to prove risk and functionality. Despite being proven safe in comparison with other marketable technologies, the more political challenge remains in its adoption to clinical practice whilst physicians and patients still lack confidence and trust.89 Therefore, whilst reporting criteria and regulatory bodies are hurdles which may be succeeded by improvements previously outlined, AI/ML will face an uphill popularity battle before earning a place at the clinician’s desk.
The present meta-analysis is one of few systematic reviews and meta-analysis interpreting the performance of AI in ophthalmology. It comprises a total of 42 studies based on 23 different databases, and our results suggest that AI has immense potential in ophthalmology for image interpretation. The breadth of studies selected encompasses performance across various important pathological conditions in ophthalmology, highlighting the generalizability of AI for image analysis.
Despite this, our findings have several limitations. Firstly, because our aim was broadly defined and lent itself to a pooled analysis, AI performance according to ocular pathology was not investigated. Even so, our analysis shows that across most studies there is a high sensitivity, specificity, and AUC. Secondly, we excluded studies that did not report performance indicators like sensitivity, specificity, accuracy, and AUC. This limited the scope of eye diseases available for analysis. Thirdly many studies have various methodological deficits as detailed earlier, making their reported diagnostic accuracy potentially unreliable, and our pooled accuracy potentially an overestimation of true accuracy in real-world practice. Fourthly we were not able to assess the selected studies against any standard reporting framework as AI-specific reporting guidelines including SPIRIT-AI,67 CONSORT-AI68, STARD-AI15, and TRIPOD-AI69 are not widely adopted by current literature. Lastly, our study aimed to have a comprehensive overview of AI in ophthalmology, it was beyond our scope to statistically compare between different imaging modalities, thus leading us to accept their innate differences. Despite this, the imaging modalities used are all diagnostically accepted means of screening for eye diseases.
A primary concern after analyzing the chosen studies was their significant heterogeneity. This may limit the generalizability of AI performance. Reporting standards for ML related studies across the globe are currently unsatisfactory, and with AI being of great ethical concern there needs to be a governing force for regulating its use in research and clinical practice. The universal adoption of SPIRIT-AI, CONSORT-AI, TRIPOD-AI, and STARD-AI frameworks in future studies will eliminate inconsistencies, homogenize means of data reporting and ensure data reproducibility.90 While the integration of AI into healthcare is likely to be widespread in the future it remains a current challenge for clinicians and patients to fully trust the potential of AI/DL. Therefore, guidelines to regulate AI use and build appropriate ethical legislation to safeguard concerns pertaining to medical error, control over AI, and patient data protection need to be developed in a timely fashion.
The following would benefit for streamlining AI into ethical legislation; 1) encouraging the external validation of DL and AI systems from clinicians or experienced graders to reach a ground truth, 2) guiding methods for determining appropriate training and test set size and 3) mandatory reporting of sensitivity, specificity, accuracy, and AUC. By adopting the recently constructed frameworks for reporting AI, studies will become more reliable in their relatedness to clinical practice and deemed more trustworthy by design.
AI is a rapidly evolving field with immense potential in healthcare. This study has demonstrated AI has high and, in some cases, excellent performance in the field of ophthalmology. These technologies may soon play an increasingly significant role in the diagnosis and treatment of ocular pathologies. The adoption of standardized reporting frameworks and more prospective/randomized control trials are currently required to improve generalizability of AI for clinical practice.
Short running title: Artificial Intelligence and ophthalmology.
Conflict of interest: The authors have no conflicts of interest to disclose.
Funding sources: This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sector. The authors have no financial relationships relevant to this article to disclose.
Acknowledgment: None
Data statement: The data that support the findings of this study are available on request from the corresponding author.














Open Access By Aditum Open Access Journals id licensed under Creative Commons Attribution 4.0 International License. Based On a Work at aditum.org